


Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
朝比 祐一; Padioleau, T.*; Latu, G.*; Bigot, J.*; Grandgirard, V.*; Obrejan, K.*
第36回数値流体力学シンポジウム講演論文集(インターネット), 8 Pages, 2022/12
本論文では、運動論的プラズマシミュレーションコードを例としてC++ parallel algorithm (stdpar)による性能可搬実装について論じる。言語標準の並列アルゴリズムstdparと抽象的高次元配列mdspanにより、可読性および生産性を損なわずに性能可搬な実装が可能であることを示す。抽象化により性能可搬性を実現するKokkosや、指示行によって性能可搬性を実現するOpenMPとの比較により、stdparの性能,可搬性,生産性などを論じる。Intel Icelake, NVIDIA V100およびA100 GPUにおいて、stdpar版のアプリケーションの性能はKokkos版に対し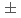 20%の範囲であった。将来的にAMDやIntel GPUにおいて利用可能になるという前提であれば、stdparはエクサスパコンにおいて有力な高生産かつ性能可搬な実装手法となり得る。
20%の範囲であった。将来的にAMDやIntel GPUにおいて利用可能になるという前提であれば、stdparはエクサスパコンにおいて有力な高生産かつ性能可搬な実装手法となり得る。
朝比 祐一; Padioleau, T.*; Latu, G.*; Bigot, J.*; Grandgirard, V.*; Obrejan, K.*
Proceedings of 2022 International Workshop on Performance, Portability, and Productivity in HPC (P3HPC) (Internet), p.68 - 80, 2022/11
被引用回数:0 パーセンタイル:0(Computer Science, Theory & Methods)本論文では、C++ parallel algorithmによる性能可搬な運動論的プラズマシミュレーションコードの実装について論じる。言語標準の並列アルゴリズムstdparと抽象的高次元配列mdspanにより、可読性および生産性を損なわずに性能可搬な実装が可能であることを示す。Intel Icelake、NVIDIA V100およびA100 GPUにおいて、アプリケーションの性能はKokkos版に対し 20%の範囲であった。将来的にAMDやIntel GPUにおいて利用可能になるという前提であれば、C++ parallel algorithmはエクサスパコンにおいて有力な高生産かつ性能可搬な実装手法となり得る。
朝比 祐一; Latu, G.*; Bigot, J.*; Grandgirard, V.*
Proceedings of 2021 International Workshop on Performance, Portability, and Productivity in HPC (P3HPC) (Internet), p.79 - 91, 2021/11
本論文では、性能可搬な運動論的プラズマシミュレーションコードのための最適化手法について論じる。まず、性能可搬ライブラリKokkosと指示行(OpenACC/OpenMP)により、単一実装でCPU、GPUで実行可能な運動論的プラズマシミュレーションコードを開発した。これに最適化を施し、Intelや富士通のCPUおよびNvidia GPUにおいて最適化の効果を評価した。その結果、OpenACC/OpenMPでは1.07倍から1.39倍の性能向上が見られ、Kokkos版では、1.00倍から1.33倍の性能向上が見られた。複数の実装による様々なカーネルの最適化手法の効果を多数のデバイスにおいて調査した本成果は、最適化手法として幅広く利用可能と言える。Kokkosは複数のデータ構造やループ構造を単一コードによって表現することに長けており、CPUとGPU両方において高い性能を発揮するために適したフレームワークであると確認した。
朝比 祐一; Latu, G.*; Bigot, J.*; Grandgirard, V.*
Proceedings of Joint International Conference on Supercomputing in Nuclear Applications + Monte Carlo 2020 (SNA + MC 2020), p.218 - 224, 2020/10
エクサスケール計算機時代には、CPUやGPUの種類を問わずに高性能を発揮する性能可搬性が重要となることが予想される。発表者は、どのような技術を活用すれば運動論的モデルを採用するプラズマ乱流コードの高可搬性実装が可能となるかを調べた。運動論的コードの例として仏国CEAで開発されたGYSELAコードに着目し、当該コードを特徴付ける高次元性(4次元以上)とSemi-Lagrangianスキームといった特徴を抽出したミニアプリケーションを作成した。発表者はミニアプリケーションをOpenACC, OpenMP4.5およびKokkosを用いて並列化し、それぞれの手法の利点,欠点を調査した。OpenACCおよびOpenMP4.5は指示行を挿入することで、Kokkosは高レベルな抽象化を行うことで性能可搬実装を実現する。発表では、生産性,可読性,性能可搬性の観点からそれぞれの手法の利点,欠点を論じる。
長家 康展; 足立 将晶*
Proceedings of International Conference on Mathematics & Computational Methods Applied to Nuclear Science & Engineering (M&C 2017) (USB Flash Drive), 6 Pages, 2017/04
MVPは連続エネルギー法に基づく汎用中性子・光子輸送モンテカルロコードである。MVPコードの高速化を図るため、メッセージ・パッシング・インターフェースライブラリMPIと共有メモリ・マルチプロセッシングライブラリOpenMPを用いてハイブリッド並列化を行った。高速炉集合体の固有値計算、中性子・光子結合問題の固定源計算、PWR全炉心モデルに対する計算に対して性能評価を行った。比較は、4プロセス並列のMPI並列計算と4プロセス並列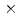 3スレッド並列のハイブリッド並列の計算時間と使用メモリ量に対して行った。その結果、ハイブリッド並列は16%から34%の計算時間削減を達成し、使用メモリ量はほとんど変わらないことが分かった。
3スレッド並列のハイブリッド並列の計算時間と使用メモリ量に対して行った。その結果、ハイブリッド並列は16%から34%の計算時間削減を達成し、使用メモリ量はほとんど変わらないことが分かった。
古田 琢哉; 佐藤 達彦; 小川 達彦; 仁井田 浩二*; 石川 顕一*; 野田 茂穂*; 高木 周*; 前山 拓哉*; 福西 暢尚*; 深作 和明*; et al.
Proceedings of Joint International Conference on Mathematics and Computation, Supercomputing in Nuclear Applications and the Monte Carlo Method (M&C + SNA + MC 2015) (CD-ROM), 9 Pages, 2015/04
粒子・重イオン輸送計算コードPHITSには計算時間短縮のために、二種類の並列計算機能が組み込まれている。一つはメッセージパッシングインターフェイス(MPI)を利用した分散メモリ型並列計算機能であり、もう一つはOpenMP指示文を利用した共有メモリ型並列計算機能である。それぞれの機能には利点と欠点があり、PHITSでは両方の機能を組み込むことで、利用者のニーズに合わせた並列計算が可能である。また、最大並列数が8から16程度のノードを一つの単位として、数千から数万というノード数で構成されるスーパーコンピュータでは、同一ノード内ではOpenMP、ノード間ではMPIの並列機能を使用するハイブリッド型での並列計算も可能である。それぞれの並列機能の動作について解説するとともにワークステーションや京コンピュータを使用した適用例について示す。
堀越 将司*; 上島 豊; 久保 憲嗣*; 若林 大輔*; 西原 功修*
ハイパフォーマンスコンピューティングと計算科学シンポジウム(HPCS 2005)論文集, p.65 - 72, 2005/01
日本原子力研究所関西研究所に設置されている超並列コンピューターJAERI SSCMPPシステムの評価を行った。今回の評価により大規模システムにおいて、各SMPノードのすべてのプロセッサを使うとパフォーマンスの顕著な低下、特に通信周りの大幅な性能低下が起こり各ノードで1プロセッサを使わない場合よりも性能が劣ることが明らかになった。全プロセッサを使用する場合では、さまざまな試行により最大で15%程度の性能向上を得ることができた。しかしながら、各SMPノードで1プロセッサを使わない場合よりも良い性能を出すことはできなかった。ハイブリッド法(MPI/OpenMP)では、全プロセッサを使用した場合で最も良い性能を記録することができた。また、ハイブリッド法は、OpenMPの実装が向上すれば、さらなる性能向上が見込めることが明らかになった。
朝比 祐一; Latu, G.*; Bigot, J.*; Grandgirard, V.*
no journal, ,
性能可搬な運動論的プラズマシミュレーションコードの実現に向けて、単純化されたミニアプリを開発し、それを性能可搬ライブラリKokkosと指示行によってCPU, GPUで並列実行可能にした。可搬性を高めるため、Kokkosと指示行実装どちらにおいてもコードをCPUとGPUで別途実装することは避け、単一実装でCPU, GPUで並列実行可能とした。開発したミニアプリの性能を富士通A64FX, Nvidia GPUおよびIntel CPUで性能測定した。これらのアーキテクチャはエクサスケールスーパコンピュータにおいて主要な候補になっている。NvidiaやIntelにおいては良好な性能が得られたものの、A64FXにおいてはメモリの間接参照により大幅に性能が大幅劣化することが明らかとなった。講演では、可読性や生産性を高めるためのKokkosや指示行での実装方法についても論じる。
朝比 祐一
no journal, ,
性能可搬な運動論的プラズマシミュレーションコードのための最適化手法について論じる。まず、性能可搬ライブラリKokkosと指示行(OpenACC/OpenMP4.5/OpenMP)により、単一実装でCPU、GPUで実行可能な運動論的プラズマシミュレーションコードを開発した。これに最適化を施し、Intel CPUおよびNvidia GPUにおいて最適化の効果を評価した。その結果、OpenACC/OpenMPでは1.07倍から1.39倍の性能向上が見られ、Kokkos版では、1.00倍から1.33倍の性能向上が見られた。複数の実装による様々なカーネルの最適化手法の効果を多数のデバイスにおいて調査した本成果は、最適化手法として幅広く利用可能と言える。Kokkosは複数のデータ構造やループ構造を単一コードによって表現することに長けており、CPUとGPU両方において高い性能を発揮するために適したフレームワークであると確認した。
Grandgirard, V.*; 朝比 祐一; Bigot, J.*; Bourne, E.*; Dif-Pradalier, G.*; Donnel, P.*; Garbet, X.*; Ghendrih, P.*
no journal, ,
将来の核融合装置のためにはプラズマ乱流輸送や熱輸送を理解することが重要である。プラズマコアの乱流については非線形の5次元ジャイロ運動論コードによってモデル化可能である。一方で、境界壁付近のプラズマのエッジ領域のモデル化は困難となっている。これらを同時にモデル化するためにはエクサスケール計算機が必須である。エクサスケール計算の準備として、OpenMP4.5taskレベル並列に関する取り組みや、Kokkosによる性能可搬実装のためのコード再設計について説明する。
